In this posting I will be explaining how to automate the unit testing, code coverage and code quality analysis that we did manually in the first two posts.
As the title of this series suggests, I use Jenkins for this automation (also known as continuous integration - ci). In keeping with the theme of using apt for everything, I will install Jenkins via apt. That being said, in my real job, I have downloaded a jenkins.war file from the Jenkins web site and I start it up from the command line.
Install and start Jenkins
Jenkins appears in the default apt that ships with Ubuntu, but it's a really old version... so old, in fact, that it won't run the plugins that we'll need in order to do the code quality and code coverage analysis. To get around this, refer to these instructions on the Jenkins web site to update your apt sources and get the latest version Jenkins via apt.Here's a quick screen-shot of the instructions you'll need to follow:

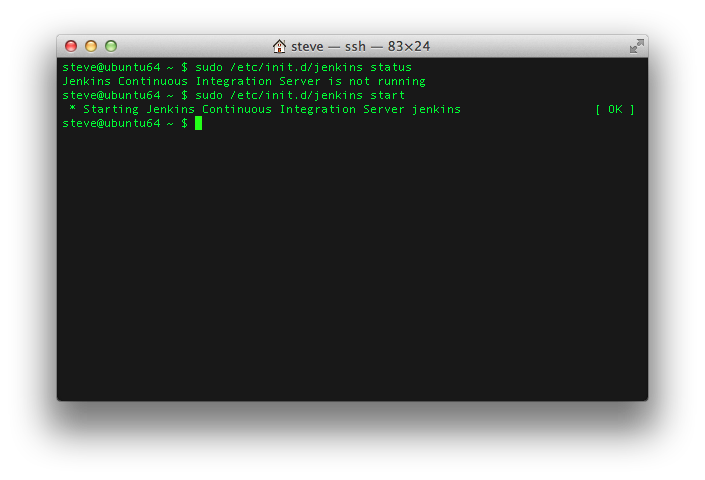
Once you've got Jenkins installed, check to see if Jenkins is running. If it isn't start it.
sudo /etc/init.d/jenkins status
sudo /etc/init.d/jenkins start

Install some needed Jenkins plugins
Jenkins has lots of plugins that will allow it to do lots of interesting things. We will be needing a few of them. To install plugins, click on the Manage Jenkins link from the list of links on the left-hand side of the page. Next click on the Manage Plugins link from the resulting page. Finally click on the Available tab from the Plugin Manager page.
- Jenkins Cobertura Plugin
- Jenkins GIT plugin
- Jenkins Violations
After you've check the checkboxes, click the Download now and install after restart button at the bottom of the page.

Our first job
When Jenkins comes back, click the New Job link from the left-hand list of links. This will bring you to a page where you can enter a job name and select a job type. Enter Project1 for the job name and select Build a free-style software project, then click the OK button.
1 - Where to get the source
Under the Source Code Management section, click the Git radio button. This will expand more options. For this project we'll be keeping things simple. Simply enter the path to your git repository. Mine's at /home/steve/dev/project1 (this presumes your git repo is on the same box that Jenkins is running on).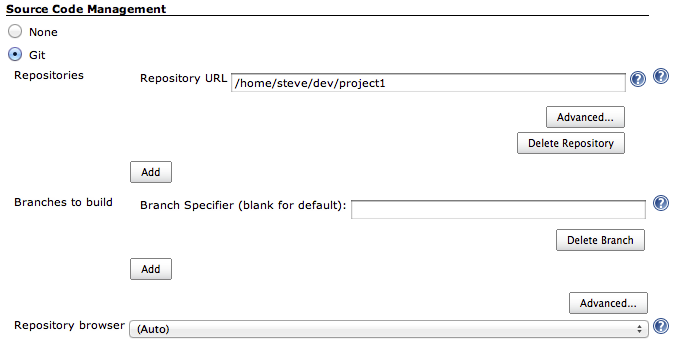
2 - When to run the job
Next go to the Build Triggers section and check the Poll SCM checkbox. In the resulting Schedule field, enter 5 *'s. (* * * * *) This makes Jenkins check the git repository for changes once a minute, every minute of every day. If it finds a change in the repository, it will "do a build". We'll be configuring "the build" to run the unit tests and code coverage and quality tests for us.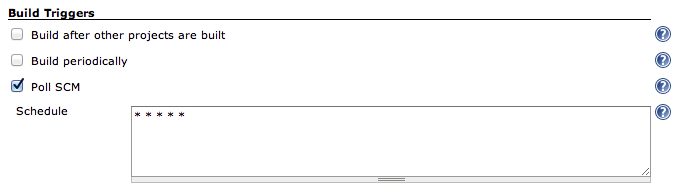
BTW, for larger Jenkins implementations (more than 10 or so Jenkins jobs), the Poll SCM option is a terrible idea. I can show you another way using git hooks if there is interest. For now, though, let's just use the Poll SCM option since this is just an example project.
3 - What to run
Next, let's configure the job to do what we want it to when it detects a change in the git repository. In the Build section, click the Add build step button and select Execute shell from the resulting popup. In the resulting Command field, enter the following text:Let's review what's going on here. When the Jenkins job detects that a source code change has occurred in the git repository, it will clone a copy of the repository and then run the above script against the clone.
You'll notice that the nosetests command has become a little more complex. I've added a fair number of command-line arguments to it. This is to make sure that the code coverage runs over all the code, not just the code that's involved in the unit tests. It also ensures that nosetests write's it's output to a file that Jenkins can interpret.
When nosetests runs the code coverage, it generates a .coverage file. Jenkins can't read that. The third line of the script (python -m coverage xml...) converts the .coverage file to an xml format that Jenkins Cobertura plugin can read.
The last line (pylint...) runs pylint on the project and outputs it in a format that the Violations Jenkins plugin can read. I also have it disabling a couple warnings that I don't care to know about. (You can customize this all you want BTW).

4 - Interpret the results
Not only can Jenkins detect changes and run our tests. Given the correct plugins are installed (which we did at the beginning), it can interpret the results and display them in charts/trees/etc. For me this is the best part. All the other stuff, I could have done with some clever scripting and cron.First stop is coverage. In the Post-build Actions section click the Public Cobertura Coverage Report checkbox. Then in the Cobertura xml report pattern field, enter coverage.xml.

This tells Jenkins to read a file named coverage.xml that will contain testing code coverage information in it. The line listed below (from the build script in step 3) is what creates this file:
python -m coverage xml --include=project1*
Next, click the Publish JUnit test result report checkbox and enter nosetests.xml in the Test report XMLs field.

This instructs Jenkins to interpret the a file named nosetests.xml that the nose command from creates:
nosetests --with-xunit --all-modules --traverse-namespace --with-coverage --cover-package=project1 --cover-inclusive
Finally, check the Report Violations checkbox and enter **/pylint.out in the pylint field.

This instructs Jenkins to interpret the pylint.out file that is generated by the pylint command from the build script:
pylint -f parseable -d I0011,R0801 project1 | tee pylint.out
At this point, you're done configuring the job. Click the Save button. Now you're ready to give it a go!
Run the job
Click the Build Now link on the left-hand list of links. This will manually kick off a run of the job. If no errors. You should see a screen that looks like the one below. If not refresh your page.
Update the code
Add the following code to your ~/dev/project1/project1/authentication.py file. Then save and commit it.def logout():
print 'You are now logged out.'


No go back to your Jenkins window and refresh the Project1 page. You may need to wait a minute. Remember, Jenkins only checks the git repository for changes once a minute. You should see some new info. The top graph is your code coverage. It indicates that you've dropped from 100% line coverage to 92%. This makes sense because we added function, but no test for it.
The second graph is your unit test pass/fail trend. It's all blue because all 3 of our tests are still passing. We'll break that next by adding a test for logout that fails. :-)
The third graph is your code quality report. It's indicating that we had 0 issues in the first build, but now have 1 issue in the second build.
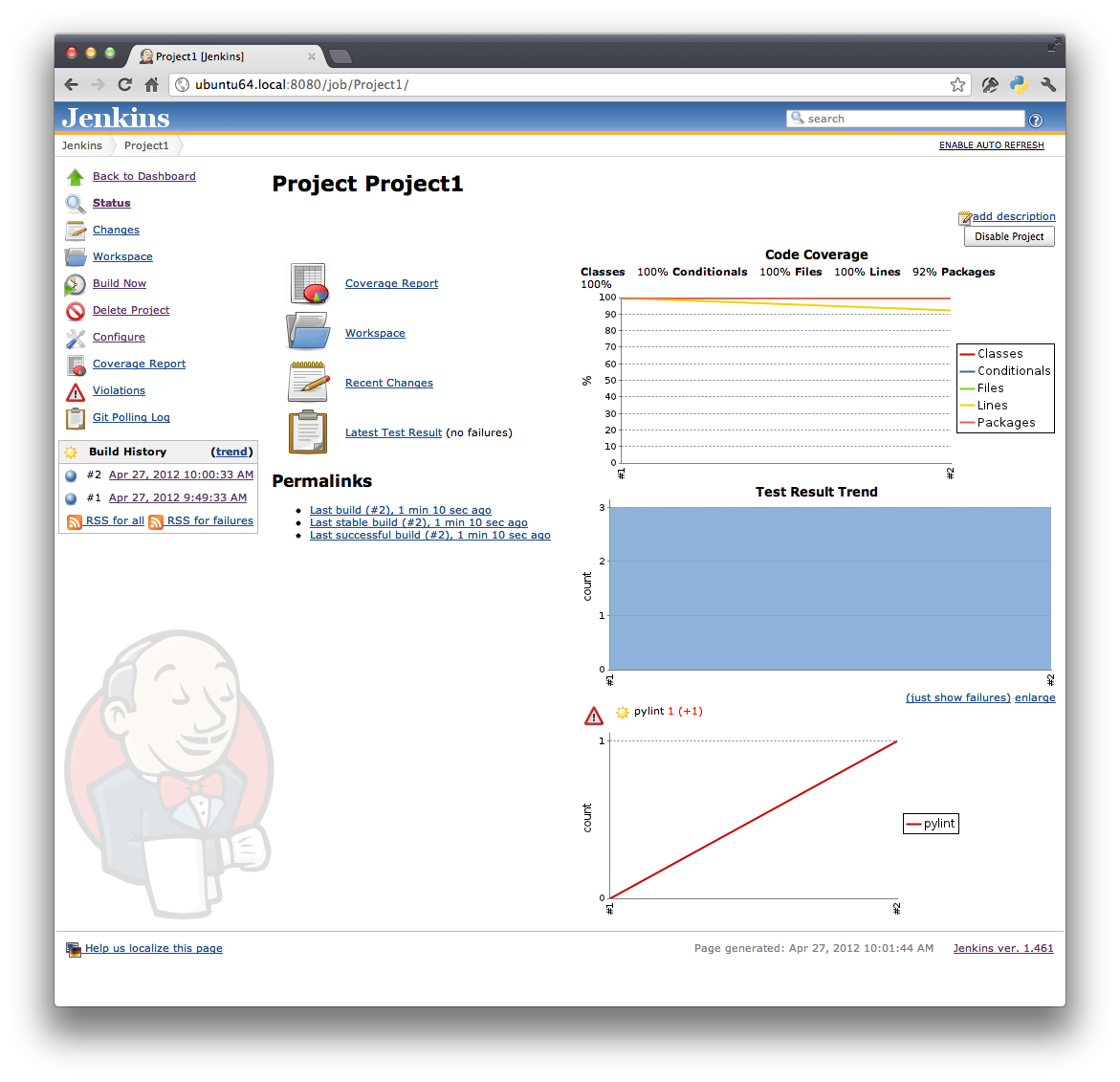
You can get more info by clicking on the graphs. For example, let's drill into the code coverage graph.

You can browse even deeper. Click on the project1 link at the bottom.

Then click on the authentication.py link at the bottom.

As you can see by the red line at the bottom, the print statement at the bottom is never exercised by a unit test. Hmmmm. We'll need to fix that.
Add a failing test
Add this code to the ~/dev/project1/tests/authentication_tests.py file and then commit it to git:
def test_logout(self):
"""Test the logout function...badly."""
self.assertEqual(0, 1)

Wait a minute and then go back to the Jenkins Project1 page. It should now have a third build reporting the test failure.

That's it. Hope you found this helpful. Happy coding.